
Important Components and SEO Tips for Online Success
Estimated Read Time: 12 minutes
Intended Audience: B2B Business Owners, Chief Marketing Officers, Business Strategists
Last updated March 15, 2021
How often do we hear that the big things are the little things? In the case of launching a new website or a website redesign, spoiler alert, it all comes down to the little things. You can have the most beautifully designed website, a perfectly architected site structure, and even best-practice search engine optimization tactics, but if you miss the all-important technical elements, there’s a good chance that your site will end up in the boonies when it comes to search engine results. And what good is your beautiful new website, with perfectly crafted content if it doesn’t get any visitors?
What is a Sitemap and do I need one?
Should I Include Every Webpage in the XML Sitemap?
The short answer is no. You probably don’t want all of the pages on your website indexed so it’s ineffective to indicate that all webpages contain quality content that ought to be indexed, when in reality this doesn’t apply to every page on your website. For example, is the ‘Thank You for Contacting Us’ page that appears when a visitor submits a ‘Contact us’ form, high-quality content that’s worthy of indexing? Probably not.
It’s common practice to have a number of pages on your website like this that fall into the category of ‘utility’ pages. This is totally expected but it’s fundamental to keep such utility pages away from your Sitemap because if they’re included it can indicate to Google that you don’t understand the meaning of quality content in the context of search engine results pages (SERPs). On the other hand, if your website contains 250 pages, 100 of which are utility pages that are omitted from your XML sitemap and 150 of which are included in your sitemap as they contain content that’s relevant for indexing and display on SERPs, then you’re sending a clear message to Google and increase your chances of ranking for quality content.
Consistency is vital when it comes to communicating with Google. So if you include a page as “noindex” in your robots.txt file then it shouldn’t be included in your XML sitemap. Just because you’ve omitted some pages from your sitemap doesn’t mean they won’t appear on search engine results pages (SERPs). For pages that you wish to hide from (SERPs), you’ll have to create a robots.txt file, as explained in detail below.
How do I create a Sitemap?
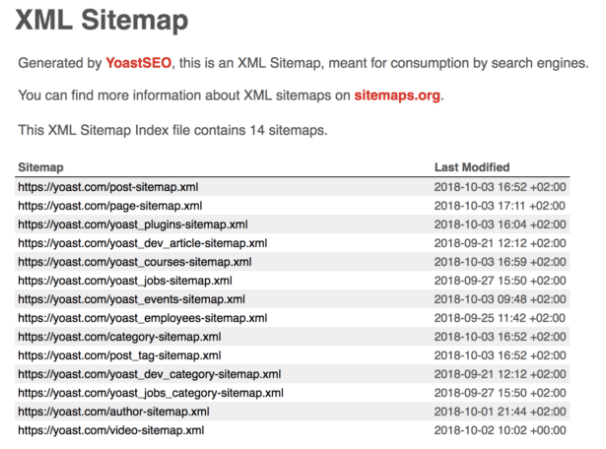
The good news is there are lots of tools available to help with this, most of which are free. Yoast is available as a plug-in for WordPress and can be used as an effective tool to easily create an XML sitemap. Once Yoast has been installed, simply enable the plugin by clicking on the features tab and then enable ‘Advanced settings pages’. Once Yoast has been enabled on WordPress, a tab for ‘XML Sitemaps’ will appear on the sidebar. Simply set this to ‘enabled’ and you’re off to the races, your sitemap has been created! Once you’ve created your sitemap, it needs to be submitted to Google (through Search Console) and Bing (through Webmaster Tools) it’s that easy.
What is a Robots.txt file?
A robots.txt file is a useful file created by webmasters to instruct web robots, typically search engine crawlers, how to crawl pages on their websites. A robots.txt file is part of the Robot Exclusion Protocol (REP), which are web standards that manage how bots crawl websites and index content to serve on search engine results pages (SERPs).
Robots.txt files essentially notify ‘user-agents’ which is another name web-crawling bots, about which pages they should ‘follow’ or not follow (‘no follow’) when indexing websites to present search results. User agents can be called out individually for specific actions (e.g. The command following ‘User-agent: Googlebot’ is a command specifically to Google) and ‘User-agent: *’ is used when the webmaster wishes a command to apply to all bots crawling their site.

Why Block a Search Engine from Indexing a Webpage?
There are four main reasons why it makes sense to block search engine crawlers from indexing a webpage using the robots.txt file. First, if you have webpages with duplicate content then it makes sense to block duplicate pages from being indexed as duplicate content can negatively affect your SEO. Second, some webpages are presented when an action is completed. For example, a thank you webpage is often displayed after a form is completed. In this instance, you probably don’t want a search engine to index the thank you page, as it only makes sense for it to be displayed after an action is taken. Third, perhaps you want to use a robots.txt file to stop a search engine from indexing a page to maintain privacy but bear in mind that not all bots adhere to the stipulations of a robots.txt file. Lastly, robots.txt files can help keep your bandwidth from being used up by search engine robots indexing your images, which can impact page load speed, again something that can negatively impact your SEO.
How to Create a Robots.txt file
Thankfully, Google makes this process pretty straightforward, all you have to do is set up a free Google Search Console account and create a robots.txt file with the following steps:
- Click on ‘Generate robots.Txt’.
- Under the ‘Action’ tab, select ‘Block’.
- Under the ‘User Agent’ tab, you can choose to block ‘all robots’ from crawling the specified pages or just block particular robots e.g. Google-mobile.
- Add relative links (e.g /Thank-you rather than www.websitedomain.com/thank-you’) to the pages you wish to block under ‘Directories and Files’.
- Click on ‘Add rule’ to create a rule for specified pages.
- ‘Download your robots.txt file’ to generate the robots.txt file as specified.
- Once you’ve successfully created a robots.txt file, it needs to be uploaded to the root of your domain as a text file. The file should be named robots.txt and /robots.txt should be the URL for your robots.txt file.
Don’t forget to update your robots.txt file as you update your website with pages that you don’t want to be indexed by search engines to maintain the privacy of your website while getting the best out of your search engine optimization activities. Below is an example of the New York Times’ robots.txt file:

Essential Robots.txt file Commands
User-agent: This refers to the web crawling robot to that is being addressed for a specific command. It’s important to note that some search engines have multiple user agents e.g. ‘Googlebot’ refers to Google’s crawler for organic search and ‘Google-bot image’ for image search. Most user agents from the same search engine follow the same rules so it’s not necessary to specify for each of their user agents, but it’s handy to have the ability to do so when appropriate.
Allow: This command only works with Googlebot (Google’s user agent) and encourages the bot to crawl a specified webpage, even if the parent page or subfolder has been blocked. A separate command is required for each webpage you wish to allow.
Disallow: This command tells the specified user agent not to crawl the specified page. A separate command is required for each webpage you wish to disallow. Moreover, Disallow: /images/ tells the Googlebot crawler to ignore all images on your site. Disallow: /ebooks/* .pdf tells crawlers to ignore all your PDF formats which may cause duplicate content issues.
Crawl-delay: This directs a user agent to wait for a number of seconds before crawling a page. This command is not followed by Googlebot, however, a crawl-delay can be set in Google Search Console as required.
Sitemap: This is used to specify the location of any XML sitemaps that are associated with a particular webpage. This command is supported by Google, Bing, and Yahoo.
No Follow: This command directs a user agent not to follow the outbound links included on the page.
Robots.txt Tips for Success:
- Robots.txt files are publicly accessible, simply add ‘/robots.txt’ to the end of a website domain to view its robots.txt file, so don’t use it to hide sensitive information, as anyone can see which pages the webmaster wants to be crawled or not crawled.
- A robots.txt file must be placed in the website’s top-level directory (typically in the root domain or homepage) to be successfully found and interpreted by user agents, otherwise, it’s likely to be unfound and therefore disregarded.
- A robots.txt file is case sensitive and the file must be called ‘robots.txt’ and no other variation.
- A subdomain on a root domain uses separate robots.txt files e.g. blog.domain.com and domain.com, so it’s important to create two separate robots.txt files for each.
- Best practice suggests adding the sitemap location at the bottom of a robots.txt file.
- Make sure you’re not blocking any sections of your site that you do want to be crawled as this can have a detrimental impact on your SEO practices.
- Some user agent robots disregard the robots.txt file, particularly malicious crawlers that skim information.
- Search engines typically cache robots.txt files and update them once a day so if you make changes to your robots.txt file and want them to be incorporated sooner than that, simply submit the new robots.txt file URL through Google Search Console.
Why Should You Use Robots.txt?
You may be aware that is not that crucial to include robots.txt in your website, but there are some critical benefits to it:
- You can let crawlers know where your sitemap is located so that they can scan it through.
- It prevents bots from indexing private folders by pointing them away from them. It also prevents them from indexing duplicate pages.
- Site resources are easily exhausted if bots crawl each and every page, especially in the case of large e-commerce sites. Using robots.txt makes it harder for bots to access individual scripts and images, therefore, retaining valuable resources for real visitors.
This is an efficient and effective way to direct search engines to the most important and relevant pages of your website. Did you know Google errors on the safe sides and assumes sections should be restricted rather than unrestricted if the directives given are uncertain or confusing. Turns out Google’s robots.txt interpreter is rather forgiving!
Search Console - Waste of Time or Time Well Wasted?
If you’re familiar with Google Webmaster Tools, chances are you know about Google Search Console, its name since 2015, to encompass the wide group of users including designers, SEO experts, and marketers. In a nutshell, Google Search Console is a free service that provides insights to help you measure your website performance, flag potential issues, and control how Google views your website. Below, you can find out how to set up Google Search Console but before you can reap the benefits, you’ll need to first add and verify your authority to access the website. Given the confidential nature of the information supplied, Google needs to ensure that you’re the site owner or webmaster before sharing the delights of Google Search Console with you.
How to Set up Google Search Console
1. Log into your Google Search Console account, enter the website URL and click ‘Add property’ to get started.
2. Next, you’ll be presented with the four options below to complete Google Search Console verification – HTML file, HTML tag, Google Analytics, Google Tag Manager or Domain name provider.

What’s the Difference between Google Search Console and Google Analytics?
While both free tools provide information that relates to your website, the information provided is different. Google Analytics focuses on information around visitors to your site such as how they arrive at your website, time spent on each page, geographic region etc. On the other hand, Google Search Console is focused on highlighting issues relating to your site such as broken links, malware, keywords that drive traffic to your site.
It’s important to note that if you look at the same report in Google Analytics and Google Search Console separately, the results may be different as the tools look at the information from different perspectives. It’s worthwhile linking both accounts as you will benefit from additional reporting capabilities. Simply log into Google Search Console and once you’ve verified your website based on the steps above, and select ‘Google Analytics Properly’ from within the settings icon in the top right hand corner.
Understanding Site Errors in Google Search Console

Gain Insight into your SEO Performance with Google Search Console
Search Console can show you how often your site appears in Google search queries so that you can monitor your SEO performance. Visit the ‘Search Analytics’ tab in the ‘Search Traffic’ section of the sidebar. This gives you an insight into your search traffic over time and where your traffic is coming from.
This powerful tool provides the information you need to enhance your SEO by understanding more about your traffic source, visitor device type and which pages have the highest click-through-rates. It’s helpful to understand more about your mobile traffic so that you can ensure an effective user-experience for pages with significant mobile traffic
How to Re-Index an Updated Page or Entire Website?
You can manage and update your sitemap and robots.txt file within Google Search Console. This is particularly handy if you make changes to your website that you want Google to index fast.
- Select the ‘Crawl’ tab and then click on ‘Fetch as Google’ and you’ll be presented with a screen to enter the URL to the page that you want re-indexed. If you made changes right across your website or on your homepage, then you’ll want to leave the URL box blank so that your entire site is crawled.
- Click ‘Fetch and Render” which can take a few minutes.
- Once your site has been re-indexed, scroll to the bottom and click on the ‘Submit to Index’ button.
- Choose ‘Crawl Only this URL’ for a single page and select ‘Crawl this URL and Direct Links’ if you want to index the entire site.
- Once the indexing is complete, you’re all set! The changes will appear on Google within the next few days.
Given the powerful insights and tools provided by Google Search Console, it should be very clear that this impressive free tool is an absolute must-have for monitoring and improving your website performance!
I hope you found the above overview of sitemaps, robots.txt files and Google Search Console useful and informative for getting the technical aspects of your website in check. While sometimes overlooked, these technical components can make all the difference to achieving a successful SEO strategy, giving you the ability to take your website from good to great!
Please note: We do not actively update blog posts with new release notes from these critical SEO tools. This post should not be used as the sole source of information on how to use Sitemaps, Robot.txt and GSC.
We’d love to hear more about your experience with sitemaps, robots.txt files and Search Console, and see how we can help you achieve SEO success drop us an email at maven@mavencollectivemarketing.com


